iOS 之编译
Dependency
术语声明
在查询编译原理的过程中, 我被网上的那些不规范用语彻底给整蒙了, 首先这里对机器语言和汇编语言称呼做下总结:
- 机器指令 = 机器语言 = 机器码 = 机器代码 =
101010101010 - 汇编指令 = 汇编语言 =
mov ax,bx
为什么需要编译
计算机的核心是 CPU, CPU 中有上亿个晶体管, 运行的时候, 每个晶体管会根据电流的 关闭 与 流通 来确认两种状态, 也就是我们说的 0 或 1.
为了对计算机发送指令, 人们发明了汇编语言, 这种语言使用了人类容易理解的字母组合来表示指令, 但是计算机是理解不了这种语言的, 因此还需要通过特定的编译器将汇编语言转换为 CPU 能理解的机器语言 (二进制)
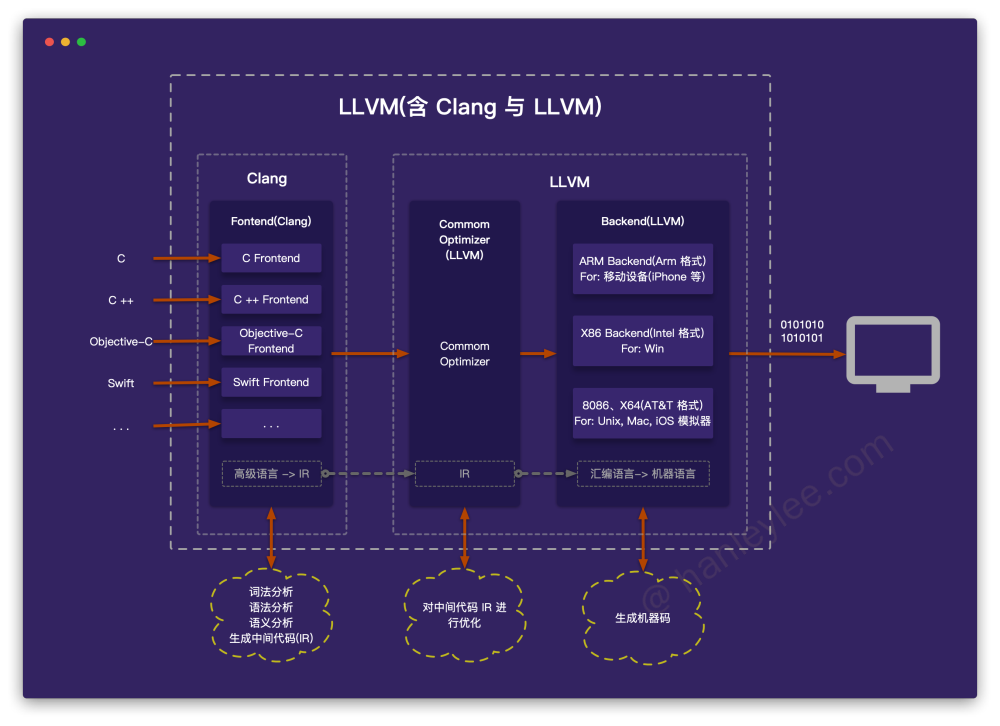
写代码时我们使用的都是高级语言 (c / c++ / java / oc / swift 等), CPU 是不认识这些语言的, 编译的过程就是将高级语言转换为 CPU 可以识别的二进制. 在 iOS 开发中, Xcode 调用 LLVM 来完成编译过程, 将 Swift 语言经历 frontend -> optimizer -> backend 转换成机器可以识别的二进制指令. 这整个过程如下图所示:
在此过程中, 语言经历了: 高级语言 -> 汇编语言 -> 机器语言 (二进制). 通过机器语言可以反编译为汇编语言, 通过汇编语言也可以反编译出高级语言, 不过很难, 因为有可能两个不同的高级语言命令产生的汇编语言是相同的
iOS 项目编译过程简介
我们的项目是一个 target, 一个编译目标, 它拥有自己的文件和编译规则, 在我们的项目中可以存在多个子项目, 这在编译的时候就导致了使用了 Cocoapods 或者拥有多个 target 的项目会先编译依赖库. 这些库都和我们的项目编译流程一致.
- 写入辅助文件: 将项目的文件结构对应表, 将要执行的脚本, 项目依赖库的文件结构对应表写成文件, 方便后面使用; 并且创建一个
.app包, 后面编译后的文件都会被放入包中 - 运行预设脚本: Cocoapods 会预设一些脚本, 当然你也可以自己预设一些脚本来运行. 这些脚本都在 Build Phases 中可以看到
- 编译文件: 针对每一个文件进行编译, 生成可执行文件 Mach-O, 这过程 LLVM 的完整流程, 前端, 优化器, 后端
- 链接文件: 将项目中的多个可执行文件合并成一个文件
- 拷贝资源文件: 将项目中的资源文件拷贝到目标包
- 编译
storyboard文件:storyboard文件也是会被编译的 - 链接
storyboard文件: 将编译后的 storyboard 文件链接成一个文件 - 编译
Asset文件: 我们的图片如果使用Assets.xcassets来管理图片, 那么这些图片将会被编译成机器码, 除了 icon 和 launchImage - 运行 Cocoapods 脚本: 将在编译项目之前已经编译好的依赖库和相关资源拷贝到包中
- 生成
.app包 - 将 Swift 标准库拷贝到包中
- 对包进行签名
- 完成打包
swiftc 与 clang 区别
不同于 OC 使用 clang 作为编译器前端, Swift 自定义了编译器前端 swiftc, 如下图所示.

这里就体现出来 LLVM 三段式的好处了, 支持新语言只需实现编译器前端即可.
对比 clang, Swift 新增了对 SIL(Swift Intermediate Language) 的处理过程. SIL 是 Swift 引入的新的高级中间语言, 用以实现更高级别的优化.
Swift 编译流程
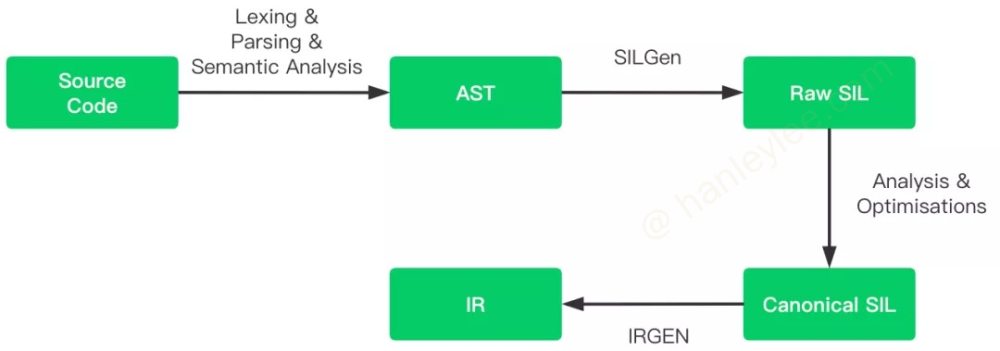
Swift 源码经过词法分析, 语法分析和语义分析生成 AST. SILGen 获取 AST 后生成 SIL, 此时的 SIL 称为 Raw SIL. 在经过分析和优化, 生成 Canonical SIL. 最后, IRGen 再将 Canonical SIL 转化为 LLVM IR 交给优化器和后端处理.
Ref
本博客文章采用 CC 4.0 协议,转载需注明出处和作者。
