iOS 开发中 GCD 使用
现在的智能设备都是多核心, 如果想让 App 充分利用多核心的性能优势, 则必须掌握多线程管理技术, 多线程管理在 iOS 开发中叫做 GCD
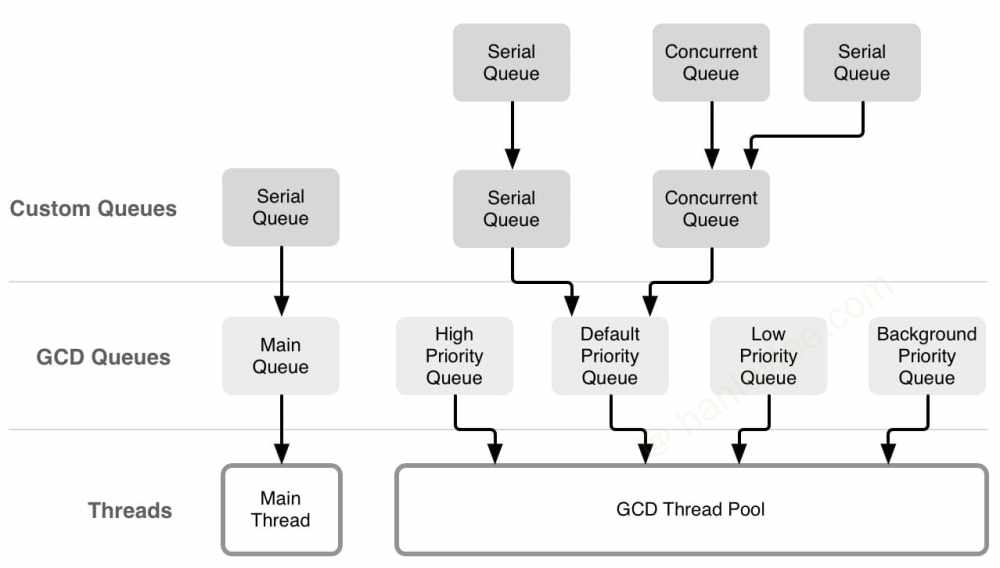
基础
- 字典与数组都是线程不安全的, 即: 多个线程同时写或一个线程写另一个线程读都会造成崩溃 (如果是读写都在一个线程则是安全的)
- 字典的读写同步造成的崩溃可通过属性观察者
didSet {}进行一定程度的缓解, 效率大概是能将 100 次的崩溃变为 1 次, 但是不能完全解决此问题 - 异步串行执行确实是只开启一个子线程, 但是如果连续不断地有一定时间间隔地往这个队列添加任务, 那么在任务结束后新任务极有可能会被分配到另一个子线程中是合理的
- 锁在 Swift 中极其难用, 因此可以避免使用锁, 转而使用 GCD 解决多线程问题
执行任务方式
- 同步 (
sync): 将新任务添加到当前任务队列的尾部, 等待队列的当前任务执行结束后执行新添加的任务, 只能在当前线程中执行任务, 不具备开启新线程的能力. - 异步 (
async): 不会做任何等待, 立刻执行新任务. 具有开启新线程的能力. 在异步执行任务过程中, 虽然具有开启新线程的能力, 但是并不一定开启新线程. 这跟任务所指定的队列类型有关 - 举例: 你要打电话给小明和小白.
同步执行就是: 你打电话给小明的时候, 不能同时打给小白. 只有等到给小明打完了, 才能打给小白 (等待任务执行结束). 而且只能用当前的电话 (不具备开启新线程的能力).异步执行就是: 你打电话给小明的时候, 不用等着和小明通话结束 (不用等待任务执行结束), 还能同时给小白打电话. 而且除了当前电话, 你还可以使用其他一个或多个电话 (具备开启新线程的能力).
队列
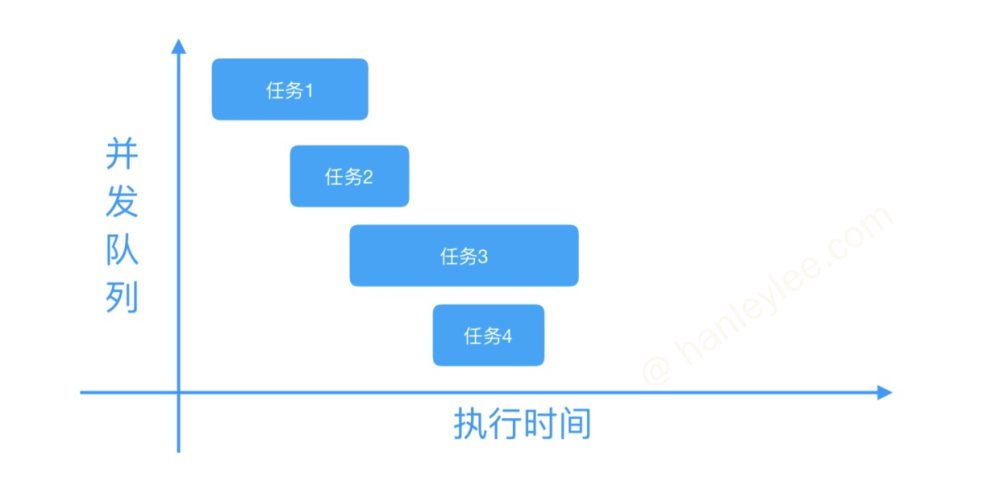
队列 | Dispatch Queue: 这里的队列指执行任务的等待队列, 即用来存放任务的队列. 队列是一种特殊的线性表, 采用 FIFO(先进先出) 的原则, 即新任务总是被插入到队列的末尾, 而读取任务的时候总是从队列的头部开始读取. 每读取一个任务, 则从队列中释放一个任务. 队列的结构可参考下图:

串行队列 | Serial Dispatch Queue: 每次只有一个任务被执行. 让任务一个接着一个地执行. (结合异步只开启一个线程, 一个任务执行完毕后, 再执行下一个任务)

并发队列 | Concurrent Dispatch Queue: 可以让多个任务并发 (同时) 执行. (结合异步可以开启多个线程, 并且同时执行任务).
主队列 | Main Queue: GCD 默认提供的
串行队列.- 默认情况下, 平常所写代码是直接放在主队列中的.
- 所有放在主队列中的任务, 都会放到主线程中执行
- 所有的主队列均不会开辟新线程. 主线程主队列中只能放异步任务, 同步任务会卡死; 子线程的主队列放同步任务不会卡死, 会将任务放在在主线程中顺序执行
- 可使用
DispatchQueue.main获得主队列.
主队列其实并不特殊. 主队列的实质上就是一个普通的串行队列, 只是因为默认情况下, 当前代码是放在主队列中的, 然后所有主队列 (包括子线程的主队列) 中的代码, 又都会放到主线程中去执行, 所以才造成了主队列特殊的现象.
UIKit 是只能在主线程工作的, 如果我们在主线程进行繁重的工作的话, 就会导致 app 出现卡死的现象: UI 不能更新
- 全局队列 | Global Queue: 系统默认的全局队列, 属于并发队列的一种, 性质与并发队列基本完全相同; 由于并发队列可以设置优先级, 因此全局队列也对应有系统预设的优先级, 由高至低依次是:
userInteractiveuserInitiateddefaultutilitybackgroundunspecified
let serialQueue1 = DispatchQueue(label: "serial") // 创建串行队列
let concurrentQueue1 = DispatchQueue(label: "concurrentQueue1", attributes:.concurrent) // 创建并行队列
let globalQueue = DispatchQueue.global(qos:.default) // 创建全局并行队列
let main = DispatchQueue.main() // 创建主队列
serialQueue1.sync { } // 串行队列同步执行, 不开新线程, 串行执行
serialQueue1.async { } // 串行队列异步执行, 开一个新线程, 串行执行
concurrentQueue1.sync { } // 并发队列同步执行, 不开启新线程, 串行执行
concurrentQueue1.async { } // 并发队列异步执行, 有多少任务开多少新线程, 并行执行
DispatchQueue.global(qos:.default).asyncAfter(deadline: DispatchTime.now() + 2) { } // 系统的全局队列 (并发队列) 异步延迟执行, 开新线程, 并行执行
DispatchQueue.main.async { } // 主队列异步执行, 不开新线程, 串行执行
DispatchQueue.global(qos:.default).async { // 并发异步, 开新线程
print("do work") // 处理耗时操作的代码块
DispatchQueue.main.async { // 操作完成, 回到主线程来刷新界面
print("main refresh")
}
}
serialQueue1.suspend() // 暂停执行队列
serialQueue1.resume() // 继续执行队列主线程中队列与任务执行方式组合
| 区别 | 并发队列 | 串行队列 | (主线程中) 主队列 | (子线程中) 主队列 |
|---|---|---|---|---|
| 同步 - sync | 不开启新线程, 串行执行 | 不开启新线程, 串行执行 | 死锁卡住不执行 | 不开启新线程, 主线程中串行执行 |
| 异步 - async | 开启新线程, 并发执行 | 开启新线程, 串行执行 | 不开启新线程, 串行执行 | - |
简单精要理解: 开不开启 新线程 完全取决于是否 异步执行
异步+串行: 只开启一条新线程(额外的)异步+并发: 追加几个任务就开几条子线程异步+主队列: 不开启新线程. 因为主队列的任务都会放在主线程中执行.异步执行会等待同步代码执行完毕后再被执行 (如果依次异步追加多个任务, 添加的多个异步任务会按照先后顺序依次执行, 这是因为主队列同时是串行队列)
注意: 从上边可看出: 主线程 中调用 主队列 + 同步执行 会导致死锁问题. 这是因为 主队列 中追加的 同步任务 和 主线程 本身的任务两者之间相互等待, 阻塞了 主队列, 最终造成了 主队列 所在的线程 (主线程) 死锁问题. 而如果我们在其他线程调用 主队列 + 同步执行, 则不会阻塞 主队列, 自然也不会造成死锁问题. 最终的结果是: 不会开启 新线程, 在主线程中串行执行任务.
队列 & 任务 & 线程 形象例子
假设现在有 5 个人要穿过一道门禁, 这道门禁总共有 10 个入口, 管理员可以决定同一时间打开几个入口, 可以决定同一时间让一个人单独通过还是多个人一起通过. 不过默认情况下, 管理员只开启一个入口, 且一个通道一次只能通过一个人.
- 这个故事里, 人好比是
任务, 管理员好比是系统, 入口则代表线程.- 5 个人表示有 5 个任务, 10 个入口代表 10 条线程.
串行队列好比是 5 个人排成一支长队.并发队列好比是 5 个人排成多支队伍, 比如 2 队, 或者 3 队.同步任务好比是管理员只开启了一个入口 (当前线程).异步任务好比是管理员同时开启了多个入口 (当前线程 + 新开的线程).
异步执行+并发队列可以理解为: 现在管理员开启了多个入口 (比如 3 个入口), 5 个人排成了多支队伍 (比如 3 支队伍), 这样这 5 个人就可以 3 个人同时一起穿过门禁了.同步执行+并发队列可以理解为: 现在管理员只开启了 1 个入口, 5 个人排成了多支队伍. 虽然这 5 个人排成了多支队伍, 但是只开了 1 个入口啊, 这 5 个人虽然都想快点过去, 但是 1 个入口一次只能过 1 个人, 所以大家就只好一个接一个走过去了, 表现的结果就是: 顺次通过入口.- 换成 GCD 里的语言就是说:
异步执行+并发队列就是: 系统开启了多个线程 (主线程+ 其他子线程), 任务可以多个同时运行.同步执行+并发队列就是: 系统只默认开启了一个主线程, 没有开启子线程, 虽然任务处于并发队列中, 但也只能一个接一个执行了.
队列的重复创建
队列是引用类型. 引用类型比较的是内存地址, 队列的 label 只是一个队列的一个属性, 两个相同 label 的队列并不一定是相同的队列.
func convertData() {
DispatchQueue(label: "custom").async {... }
}在上面这个例子中, 我们在 convertData() 这个方法中直接创建一个自定义队列, 并 异步执行. 问题的关键在于每次执行 convertData() 这个方法时都会创建一个名为 custom 的队列, 这样的话: 每次队列执行时系统会自动为队列内的任务开辟一个子线程. 如果第一次队列中的逻辑处理还没有结束的时候再次实行 convertData() 方法, 那么会再次创建一个队列并再次开辟一个新的子线程处理队列中的任务, 如果任务里操作的是一个数组或者字典类型的数据, 那么就会出现异常. 因为多个线程同时处理同一个数据的话必然是不安全的.
可以使用下面的外部创建队列方式来做:
let queue = DispatchQueue(label: "custom")
func convetData() {
queue.async {...}
}上面的代码中我们在外部创建了一个线程, 然后每次在 convertData() 方法执行时我们调用的是 queue 队列的引用, 这样就保证了从始至终一直是向同一个队列中添加任务. 而系统为此队列开辟的单个子线程在队列中的任务没有结束时会持续存在, 处理队列中的任务, 也就是说, 哪怕是在第一次的队列任务没有结束时再次执行 convertData(), 我们也只是向队列 queue 中添加任务, 因为没有新队列产生, 因此不会创建新的线程, 源源不断地 queue 队列的任务被此线程处理, 这样就保证了单个线程处理数据, 不会造成多线程处理同一个数据而造成报错.
如果此队列的任务执行完毕了, 那么由于 queue 所对应的线程 a 没有了任务需要处理, 因此线程 a 会被系统自动释放掉. 而等到下次队列中又有了任务时, 系统会重新为 queue 队列创建新的子线程 b, 但是这对于数据来说没有影响, 因为没有在两个线程同时处理数据.
迭代任务
并行队列利用多个线程执行任务, 可以提高程序执行的效率. 而迭代任务可以更高效地利用多核性能, 它可以利用 CPU 当前所有可用线程进行计算 (任务小也可能只用一个线程). 如果一个任务可以分解为多个相似但独立的子任务, 那么迭代任务是提高性能最适合的选择.
延时任务
有时候你并不需要立即将任务加入队列中运行, 而是需要等待一段时间后再进入队列中, 这时候可以使用 asyncAfter 方法.
要注意 延迟的是加入队列的时间, 而不是开始执行任务的时间.
DispatchGroup - (异步) 任务组
任务组相当于一系列任务的松散集合, 它可以来自相同或不同队列, 扮演着组织者的角色. 它可以在组内任务全部完成时通知外部队列. 或者阻塞当前的线程, 直到组内的任务都完成. 所有适合组队执行的任务都可以使用任务组, 且任务组更适合集合 异步任务 (因为如果都是同步任务, 直接使用串行队列即可).
将任务添加到 DispatchGroup 并执行
- 使用
enter,leave的方式标识加入group(步骤太繁琐, 不好用)swiftlet group = DispatchGroup() group.enter() queue.async() { // do something group.leave() } - 同一个队列添加多个异步任务到
任务组中swiftlet group = DispatchGroup() let queue1 = DispatchQueue(label: "com.flion.queue1", qos: .default, attributes: [.concurrent,.initiallyInactive]) // initiallyInactive 表示初始时是沉默的, 必须手动 active queue1.async(group: group) { print("烧开水") Thread.sleep(forTimeInterval: 2) } queue1.async(group: group) { print("煮米饭") Thread.sleep(forTimeInterval: 2) } queue1.async(group: group) { print("做 4 道小菜") Thread.sleep(forTimeInterval: 2) } queue1.activate() // 添加到 group 的所有任务执行完毕后执行 notify(notify 的顺序必须写在前面那些任务的后面) group.notify(queue: DispatchQueue.main) { print("开始吃饭喽") } 多个队列添加任务到
任务组中swiftlet group = DispatchGroup() let queue1 = DispatchQueue(label: "com.flion.queue1", qos:.default, attributes:.concurrent) queue1.async(group: group) { print("烧开水") Thread.sleep(forTimeInterval: 2) } let queue2 = DispatchQueue(label: "com.flion.queue1", qos:.default, attributes:.concurrent) queue2.async(group: group) { print("煮米饭") Thread.sleep(forTimeInterval: 2) } let queue3 = DispatchQueue(label: "com.flion.queue1", qos:.default, attributes:.concurrent) queue3.async(group: group) { print("做 4 道小菜") Thread.sleep(forTimeInterval: 2) } // 添加到 group 的所有任务执行完毕后执行 notify(notify 的顺序必须写在前面那些任务的后面) group.notify(queue: DispatchQueue.main) { print("开始吃饭喽") }如果任务所在的队列是自己创建或系统队列, 那么直接使用队列添加任务时指明 group 的方式直接加入即可
如果任务是由系统或第三方的 API 创建的, 由于无法获取对应的队列, 只能使用 enter, leave 将任务加入组内, 例如将 URLSession 的 addDataTask 方法加入任务组中.
swiftextension URLSession { func addDataTask(to group: DispatchGroup, with request: URLRequest, completionHandler: @escaping (Data?, URLResponse?, Error?) -> Void) -> URLSessionDataTask { group.enter() // 进入任务组 return dataTask(with: request) { (data, response, error) in completionHandler(data, response, error) group.leave() // 离开任务组 } } }
notify 与 wait
这两个操作都是让 group 包含的任务全部完成后执行之后的代码, 不同点自安于 notify 后面跟随闭包, 执行的是闭包的内容; wait 则是阻断当前线程的所有后续, 等待 group 内任务全部完成后再执行当前线程后续的任务
notify在所有被加入到 group 中的任务执行完毕后执行 notify 中的闭包
wait在所有任务完成后再执行当前线程中后续的代码, 因此这个操作是有阻塞当前线程的作用.
swiftlet group = DispatchGroup() let queueBook = DispatchQueue(label: "book") queueBook.async(group: group) { // do something 1 } let queueVideo = DispatchQueue(label: "video") queueVideo.async(group: group) { // do something 2 } let waitTime = DispatchTime.now() + 2.0 group.wait(timeout: waitTime) print("do something else.") // 执行结果 // do something 1(任务 1, 2 完成顺序不固定) // do something 2 // do something else.
DispatchWorkItem - 栅栏任务
public init(qos: DispatchQoS = default, flags: DispatchWorkItemFlags = default, block: @escaping @convention(block) () -> Swift.Void)DispatchWorkItem 就是一个闭包, 里面包含可执行的代码, 可以放在任何队列中执行 (即可以在主线程或后台执行), 与 DispatchGroup 类似, DispatchWorkItem 在执行完后还可以发出通知执行通知的闭包 (且还能随时 cancel).
栅栏任务的主要特性是可以对队列中的任务进行阻隔, 执行栅栏任务时, 它会先等待队列中已有的任务全部执行完成, 然后它再执行, 在它之后加入的任务也必须等栅栏任务执行完后才能执行.
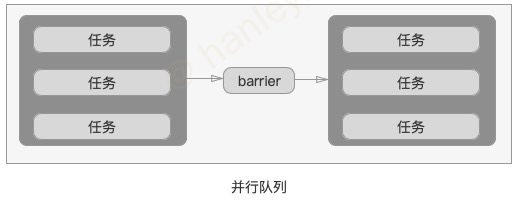
普通使用
- 直接使用swift
var value = 10 let workItem = DispatchWorkItem { value += 5 } workItem.perform() - 在队列中使用swift
var value = 10 let workItem = DispatchWorkItem { value += 5 } let queue = DispatchQueue.global(qos:.utility) queue.async { workItem.perform() } // queue.async(excute: workItem) 也可以通过本方式来执行 // 与 group 类似, workItem 可以使用 notify 执行所有任务完成后的调用, 也可以使用.wait() 达到让其内全部执行完毕后再执行当前线程剩余任务的作用 workItem.notify(queue: DispatchQueue.main) { print("value =", value) } print("value is \(value)")
DispatchWorkItemFlags
DispathcWorkItem 初始化时的 DispatchWorkItemFlags 中根据执行情况与优先级有如下选项:
- 执行情况
barrier: 如果 DispatchWorkItem 被提交到.concurrent并发队列, 那么这个DispatchWorkItem中的操作会具有独占性 (防止此DispatchWorkItem中的 block 内的操作与其他操作同时执行). 执行该任务时, 它会先等待队列中已有的任务全部执行完成, 然后它再执行, 在它之后加入的任务也必须等栅栏任务执行完成后才能执行..detached: 表明DispatchWorkItem会无视当前执行上下文的参数.assignCurrentContext
- 优先级
.noQos: 不指定 QoS, 由调用线程或队列来指定..inheritQos: 表明DispatchWorkItem会采用队列的 QoS class, 而不是当前的..enforceQos: 表明DispatchWorkItem会采用当前的 QoS class, 而不是队列的.
作为任务阻隔 (主要用于读写分离)
let queue = DispatchQueue(label: "com.ffib.blog.queue", qos: .utility, attributes: .concurrent)
let path = NSHomeDirectory() + "/test.txt"
print(path)
let readWorkItem = DispatchWorkItem {
do {
let str = try String(contentsOfFile: path, encoding: .utf8)
print(str)
} catch {
print(error)
}
}
let writeWorkItem = DispatchWorkItem(flags: .barrier) {
do {
try "done".write(toFile: path, atomically: true, encoding: String.Encoding.utf8)
print("write")
} catch {
print(error)
}
}
for _ in 0 ..< 3 {
queue.async(execute: readWorkItem)
}
queue.async(execute: writeWorkItem)
for _ in 0 ..< 3 {
queue.async(execute: readWorkItem)
}
/*
output:
test4
test4
test4
write
done
done
done
*/结果符合预期的想法, barrier 主要用于读写隔离, 以保证写入的时候, 不被读取.
进行任务的取消
假设我们的界面有个搜索框, 当用户输入一个字符, 我们通过调用后台接口来进行搜索. 用户可以很快地打字, 在这种情况下我们不能因为有一个字符输入就请求网络 (这样会浪费大量的数据和服务器容量), 实际上我们想要 防反跳 这些事件, 如果用户 0.25 秒内没有进行输入就执行一次请求.
class SearchViewController: UIViewController, UISearchBarDelegate {
// We keep track of the pending work item as a property
private var pendingRequestWorkItem: DispatchWorkItem?
func searchBar(_ searchBar: UISearchBar, textDidChange searchText: String) {
// Cancel the currently pending item
pendingRequestWorkItem?.cancel()
// Wrap our request in a work item
let requestWorkItem = DispatchWorkItem {[weak self] in
self?.resultsLoader.loadResults(forQuery: searchText)
}
// Save the new work item and execute it after 250 ms
pendingRequestWorkItem = requestWorkItem
DispatchQueue.main.asyncAfter(deadline:.now() +.milliseconds(250),
execute: requestWorkItem)
}
}DispathchGroup 与 DispatchWorkItem 结合
func groupNotify() {
let group = DispatchGroup();
let mainQueue = DispatchQueue.main;
let queue = DispatchQueue.global();
let item1 = DispatchWorkItem.init {
for _ in 0 ..< 2 {
Thread.sleep(forTimeInterval: 2)
// print("1---\(Thread.current)")
}
}
let item2 = DispatchWorkItem.init {
for _ in 0 ..< 2 {
Thread.sleep(forTimeInterval: 2)
// print("2---\(Thread.current)")
}
}
queue.async(group: group, execute: item1)
queue.async(group: group, execute: item2)
group.notify(queue: mainQueue) {
for _ in 0 ..< 2 {
Thread.sleep(forTimeInterval: 2)
print("3---\(Thread.current)")
}
}
}DispathcGroup 与 DispatchWorkItem 的区别
DispatchGroup是组的概念, 不是具体任务, 其notify适用于组内多个任务完成后的通知DispatchWorkItem是具体的单个任务, 可随时取消, 可notify, 但是此notify是指此单个任务完成后的通知
DispatchSemaphore - 信号量
信号量的使用非常的简单:
- 首先创建一个初始数量的信号对象
- 使用
wait方法让信号量减 1, 再安排任务. 如果此时信号量仍大于或等于 0, 则任务可执行, 如果信号量小于 0, 则任务需要等待其他地方释放信号. - 任务完成后, 使用
signal方法增加一个信号量. - 等待信号有两种方式: 永久等待, 可超时的等待.
let queue = DispatchQueue(
label: "com.sinkingsoul.DispatchQueueTest.concurrentQueue",
attributes: .concurrent
)
let semaphore = DispatchSemaphore(value: 2) // 设置数量为 2 的信号量
semaphore.wait()
queue.async {
print("Task 1 start")
sleep(2)
print("Task 1 finish")
semaphore.signal()
}
semaphore.wait()
queue.async {
print("Task 2 start")
sleep(2)
print("Task 2 finish")
semaphore.signal()
}
semaphore.wait()
queue.async {
print("Task 3 start")
sleep(2)
print("Task 3 finish")
semaphore.signal()
}
// 运行结果:
// Task 1 start
// Task 2 start
// Task 1 finish
// Task 2 finish
// Task 3 start
// Task 3 finishDispatchSource
GCD 中提供了一个 DispatchSource 类, 它可以帮你监听系统底层一些对象的活动, 并允许你在这些活动发生时, 向队列提交一个任务以进行异步处理. 可监听事件如下:
Timer Dispatch Source: 定时调度源.Signal Dispatch Source: 监听 UNIX 信号调度源, 比如监听代表挂起指令的 SIGSTOP 信号.Descriptor Dispatch Source: 监听文件相关操作和 Socket 相关操作的调度源.Process Dispatch Source: 监听进程相关状态的调度源.Mach port Dispatch Source: 监听 Mach 相关事件的调度源.Custom Dispatch Source: 监听自定义事件的调度源.
下面以文件监听为例看下使用方法, 下面例子中监听了一个指定目录下文件的写入事件, 创建监听主要有几个步骤:
- 通过
makeFileSystemObjectSource方法创建source - 通过
setEventHandler设定事件处理程序,setCancelHandler设定取消监听的处理. - 执行
resume()方法开始接收事件swiftlet queue = DispatchQueue.global() let filePath = "..." let fileURL = URL(fileURLWithPath: filePath) let fd = open(fileURL.path, O_EVTONLY) let source = DispatchSource.makeFileSystemObjectSource(fileDescriptor: fd, eventMask:.write, queue: queue) source.setEventHandler(handler: closure) source.setCancelHandler { close(fd) } source.resume()
DispatchSourceTimer 的例子:
func printTime(withComment comment: String){
let date = Date()
let formatter = DateFormatter()
formatter.dateFormat = "yyyy-MM-dd HH:mm:ss"
print(comment + ":" + formatter.string(from: date))
}
let timer = DispatchSource.makeTimerSource()
timer.schedule(deadline: .now() + .seconds(10),
repeating: .seconds(5),
leeway: .seconds(5))
timer.setEventHandler {
printTime(withComment: "hello world")
}
timer.activate()
printTime(withComment: "3")
// 运行结果:
// 3: 2019-04-25 16:43:53
// hello world: 2019-04-25 16:44:03
// hello world: 2019-04-25 16:44:08
// hello world: 2019-04-25 16:44:13
// hello world: 2019-04-25 16:44:18
// hello world: 2019-04-25 16:44:23DispatchIO
DispatchIO 对象提供一个操作文件描述符的通道. 简单讲你可以利用多线程异步高效地读写文件.
DispatchData
DispatchData 对象可以管理基于内存的数据缓冲区. 这个数据缓冲区对外表现为连续的内存区域, 但内部可能由多个独立的内存区域组成.
任务对象
在队列和任务组中, 任务实际上是被封装为一个 DispatchWorkItem 对象的. 任务封装最直接的好处就是可以取消任务.
概念
DispatchTime: 它通过时间间隔的方式来表示一个时间点, 初始时间从系统最近一次开机时间开始计算, 而且在系统休眠时暂停计时, 等系统恢复后继续计时, 精确到纳秒 (1/1000,000,000 秒)DispatchWallTime: 它表示一个绝对时间的时间戳, 可以直接使用字面量表示延时, 也可以借用 timespec 结构体来表示, 以微秒为单位 (1/1000,000秒)timespec: 这是 Darwin 内核中的一个结构体, 用于表示一个绝对时间点, 它描述的是从 格林威治时间 1970 年 1 月 1 日零点 开始指定时间间隔后的时间点, 精确到纳秒timeval: 这是 Darwin 内核中的一个结构体, 也用于表示一个绝对时间点, 它描述的是从 格林威治时间 1970 年 1 月 1 日零点 开始指定时间间隔后的时间点, 精确到微秒gettimeofday: 这是 Unix 系统中的一个获取当前时间的方法, 它接收两个指针参数, 执行后将修改指针对应的结构体值, 一个参数为 timeval 类型的时间结构体指针, 另一个为时区结构体指针 (时区在此方法中已不再使用, 设为 nil 即可). 方法返回 0 时表示获取成功, 返回 -1 时表示获取失败
Operation Queue
与 GCD 的不同
- 不遵循先进先出原则, 在 Operation 队列中可以设置任务执行的优先级, 并设置某些任务之间的依赖性, 即总是可以让某些任务在另一些任务之前或之后执行.
- 任务默认以并行方式执行, 甚至无法将任务以串行方式执行. (当然, 可以通过设置任务之间的依赖产生串行执行的效果)
- Operation 队列是
NSOperation类的实例, 他的任务是作为NSOperation对象的容器. (GCD 的任务以块的方式进行提交, 但是提交给Operation队列的任务必须封装在NSOperation对象中) - 可以设置最大并发量
Operation Queue 的优点
- 通过简单地方式为不同任务之间添加依赖. 可以使用
addDependency(op:NSOperation)方法添加依赖. - 可以通过
queuePriority属性来改变一个 Operation 的优先级. 取值包括swiftpublic enum NSOperationQueuePriority: Int { case VeryLow case Low case Normal case High case VeryHigh } - 可以取消指定队列的全部或单个
Operation. 在Operation上调用cancel()可以取消该 Operation, 通常在取消时会有如下三种情况- Operation 已经完成, 此时
cancel方法什么也不做 - Operation 正在执行, 系统不会强行终止
Operation中的代码, 但会将cancelled属性设置为true - Operation 位于队列中, 正在等待执行. 这种情况下系统直接取消此
Operation, 其不会被执行.
- Operation 已经完成, 此时
NSOperation有三个布尔属性finished: 当Operation执行完后,finished就会设置为 truecancelled: 当Operation被取消,cancelled会被设置为 trueready: 当Operation即将被执行,ready就被设置为 true
- 任何
Operation对象可设置一个可选的完成块. 当 finished 属性一设置为 true 后, 此块立刻被调用.
Operation Queue 实际使用
添加 Operation 进入队列
- 使用
addOperationWithBlock方法将 Operation 添加进队列中swift- @IBAction func didClickOnStart(sender: AnyObject) { queue = NSOperationQueue() queue.addOperationWithBlock {() -> Void in let img1 = Downloader.downloadImageWithURL(imageURLs[0]) NSOperationQueue.mainQueue().addOperationWithBlock({ self.imageView1.image = img1 }) } } - 使用
NSBlockOperation方法将 Operation 添加进入队列 (功能更多, 可以设置完成块)swift@IBAction func didClickOnStart(sender: AnyObject) { queue = NSOperationQueue() let operation1 = NSBlockOperation(block: { let img1 = Downloader.downloadImageWithURL(imageURLs[0]) NSOperationQueue.mainQueue().addOperationWithBlock({ self.imageView1.image = img1 }) }) operation1.completionBlock = { print("Operation 1 completed") } queue.addOperation(operation1) }
取消 Operation
@IBAction func didClickOnCancel(sender: AnyObject) {
self.queue.cancelAllOperations()
}添加依赖
// 添加依赖后, 只有 operation1 完成后, operation2 才可以被执行, operation3 同理
operation2.addDependency(operation1)
operation3.addDependency(operation2)锁
锁 (lock) 或者 互斥锁 (mutex) 是一种结构, 用来保证一段代码在同一时刻只有一个线程执行. 它们通常被用来保证多线程访问同一可变数据结构时的数据一致性. 主要有下面几种锁:
- 阻塞锁 | Blocking locks: 常见的表现形式是当前线程会进入休眠, 直到被其他线程释放.
自旋锁 | Spinlocks: 自旋锁与互斥锁有点类似, 只是自旋锁不会引起调用者睡眠, 如果自旋锁已经被别的执行单元保持, 调用者就一直循环在那里看是否该自旋锁的保持者已经释放了锁, 自旋 一词就是因此而得名. 其作用是为了解决某项资源的互斥使用. 因为自旋锁不会引起调用者睡眠, 所以自旋锁的效率远高于互斥锁. 虽然它的效率比互斥锁高, 但是它也有些不足之处:
- 自旋锁一直占用 CPU, 他在未获得锁的情况下, 一直运行自旋, 所以占用着 CPU, 如果不能在很短的时间内获得锁, 这无疑会使 CPU 效率降低.
- 在用自旋锁时有可能造成死锁, 当递归调用时有可能造成死锁, 调用有些其他函数也可能造成死锁, 如
copy_to_user(),copy_from_user(),kmalloc()等.
因此我们要慎重使用自旋锁, 自旋锁只有在内核可抢占式或 SMP 的情况下才真正需要, 在单 CPU 且不可抢占式的内核下, 自旋锁的操作为空操作. 自旋锁适用于锁使用者保持锁时间比较短的情况下.
- 互斥锁 | Mutex lock: 互斥锁属于 sleep-waiting 类型的锁. 例如在一个双核的机器上有两个线程 (线程 A 和线程 B), 它们分别运行在 Core0 和 Core1 上. 假设线程 A 想要通过
pthread_mutex_lock操作去得到一个临界区的锁, 而此时这个锁正被线程 B 所持有, 那么线程 A 就会被阻塞 (blocking), Core0 会在此时进行上下文切换 (Context Switch) 将线程 A 置于等待队列中, 此时 Core0 就可以运行其他的任务 (例如另一个线程 C) 而不必进行忙等待. 而自旋锁则不然, 它属于 busy-waiting 类型的锁, 如果线程 A 是使用pthread_spin_lock操作去请求锁, 那么线程 A 就会一直在 Core0 上进行忙等待并不停的进行锁请求, 直到得到这个锁为止. - 读写锁 | Reader/writer locks: 允许多个读线程同时进入一段代码, 但当写线程获取锁时, 其他线程 (包括读取器) 只能等待. 这是非常有用的, 因为大多数数据结构读取时是线程安全的, 但当其他线程边读边写时就不安全了.
- 递归锁 | Recursive locks: 允许单个线程多次获取相同的锁. 非递归锁被同一线程重复获取时可能会导致死锁, 崩溃或其他错误行为.
synchronized: 在创建单例对象时使用
自旋锁与互斥锁的区别
- 加锁原理
- 互斥锁: 线程会从
sleep (加锁) -> running (解锁), 过程中有上下文的切换, cpu 的抢占, 信号的发送等开销. - 自旋锁: 线程一直是
running(加锁 -> 解锁), 死循环检测锁的标志位, 机制不复杂.
- 互斥锁: 线程会从
互斥锁的起始原始开销要高于自旋锁, 但是基本是一劳永逸, 临界区持锁时间的大小并不会对互斥锁的开销造成影响, 而自旋锁是死循环检测, 加锁全程消耗 cpu, 起始开销虽然低于互斥锁, 但是随着持锁时间, 加锁的开销是线性增长.
互斥锁用于临界区持锁时间比较长的操作, 比如下面这些情况都可以考虑:
- 临界区有 IO 操作
- 临界区代码复杂或者循环量大
- 临界区竞争非常激烈
- 单核处理器
锁的 API
苹果提供了一系列不同的锁 API, 下面列出了其中一些:
pthread_mutex_t: 是一个可选择性地配置为递归锁的阻塞锁;pthread_rwlock_t: 是一个阻塞读写锁;dispatch_queue_t: 可以用作阻塞锁, 也可以通过使用 barrier block 配置一个同步队列作为读写锁, 还支持异步执行加锁代码;NSOperationQueue: 可以用作阻塞锁. 与 dispatch_queue_t 一样, 支持异步执行加锁代码.NSLock: 是 Objective-C 类的阻塞锁, 它的同伴类 NSRecursiveLock 是递归锁.OSSpinLock: 顾名思义, 是一个自旋锁.
pthread_mutex_t, pthread_rwlock_t 和 OSSpinLock 是值类型, 而不是引用类型. 这意味着如果你用 = 进行赋值操作, 实际上会复制一个副本. 这会造成严重的后果, 因为这些类型无法复制!
如果你不小心复制了它们中的任意一个, 这个副本无法使用, 如果使用可能会直接崩溃. 这些类型的 pthread 函数会假定它们的内存地址与初始化时一样, 因此如果将它们移动到其他地方就可能会出问题. OSSpinLock 不会崩溃, 但复制操作会生成一个完全独立的锁, 这不是你想要的.
至于自旋锁就主要用在临界区持锁时间非常短且 CPU 资源不紧张的情况下, 自旋锁一般用于多核的服务器.
参考资料
本博客文章采用 CC 4.0 协议,转载需注明出处和作者。
